
阿里畴昔生涯实验室 投稿
量子位 | 公众号 QbitAI
MoE(夹杂各人模子)照旧成为大模子时间的“版块谜底”。
从GPT-5到DeepSeek-V3,险些扫数最强模子背后都有MoE的影子。
但你是否想过:你模子里那几十个“各人”,可能都在干归拢件事?

在MoE预西宾中,蓝本渴望这些各人“各司其职”,终末发现他们居然“同质化”了?学术界将这种阵势称为“各人同质化”(Expert Homogenization)。这凯旋导致了MoE模子参数的挥霍和Scaling才气的封顶。
来自阿里巴巴畴昔生涯实验室的究诘团队以为,这背后是MoE预西宾流程中的信息缺失。
为了惩办这一恶疾,来自阿里巴巴集团的究诘团队提议了一种全新的各人分化学习(Expert Divergence Learning)政策。他们讹诈预西宾数据中自然存在的“鸿沟标签”,遐想了一种新的援手逝世函数,荧惑不同鸿沟的Token在路由统计信息上证实出各异,从而指引各人分化出简直的专科才气。
这一究诘(Expert Divergence Learning for MoE-based Language Models)已中稿ICLR 2026。
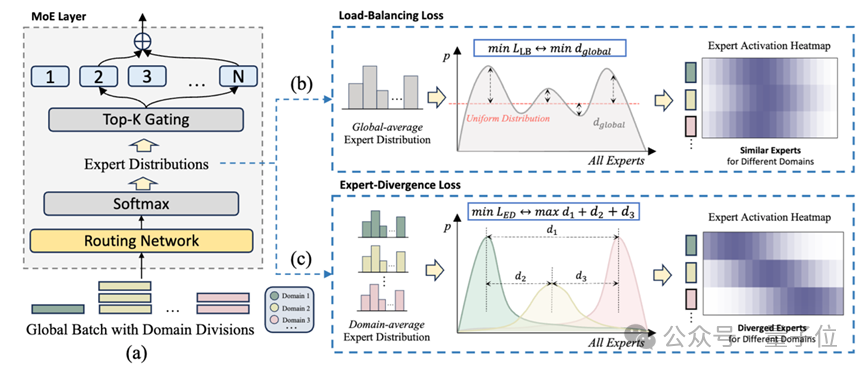
中枢洞悉:各样性≠有用单干
为什么传统的MoE西宾会导致各人同质化?团队在论文中揭示了一个被永远冷落的数学盲区。
现存的负载平衡逝世(Load-Balancing Loss)固然能提高总的路由各样性(Total Divergence),但它是一种“盲目”的擢升。它只在乎“扫数各人都被用到了”,却不在乎“是被谁用到的”。
这就好比公司发奖金,只看宇宙是不是都忙起来了,却不管是不是扫数东说念主都在重复造轮子。
阿里团队提议,简直的各人化,应该成就在“鸿沟各异”之上。需要将总的路由各样性,通过数学时间指引到“域间各异”(Inter-Domain Divergence)上。
基于此,他们提议了各人分化学习(Expert Divergence Learning)。
硬核步伐论:如安在预西宾中将就各人“分家”?
为了冲破僵局,阿里团队提议了一种刚直的、即插即用的西宾筹画函数——各人分化逝世(Expert Divergence Loss, LED)。
它的遐想灵感着手于一个优好意思的数学直观:MoE的路由各样性是不错被“解构”的。
数学旨趣:各样性主见定理(Divergence Decomposition)
论文在表面部分使用了一个要津公式:
总各样性(Dtotal) =域间各样性(Dinter) +域内各样性(Dintra)
传统作念法的劣势:已往的负载平衡Loss仅仅盲目地推高左边的Dtotal。但在费劲指引的情况下,模子倾向于通过加多Dintra(让归拢个鸿沟的Token乱跑)来吩咐检会,而不是加多Dinter(让不同鸿沟的Token分开跑)。
新步伐的Insight:LED的推行,即是精确锁定并最大化Dinter。它通过最大化不同鸿沟之间的“撤废力”,开云体育分拨总各样性的额度给“域间各异”,从而迫使各人发生功能分化。
几何直不雅:把各人“推”向角落
这个Loss的筹谋流程不错拆解为三步:
第一步:从Token到鸿沟(Aggregation)在西宾流程中,模子频繁会收受到不同着手的数据(如数学题、代码片断、新闻)。算法最初筹谋出现时Batch中,属于“数学域”的扫数Token的平均路由漫步,以及属于“代码域”的平均路由漫步。
第二步:筹谋“撤废力”(Divergence Computation)有了不同鸿沟的平均路由漫步,如何接洽它们的各异?团队采选了JS散度(Jensen-Shannon Divergence)。
JS散度是对称且有界的,极度适应用来接洽两个概率漫步的“距离”。
若是“数学各人组”和“代码各人组”的东说念主员组成高度叠加,JS散度就会很低。
若是它们使用的是两套十足不同的东说念主马,JS散度就会很高。
第三步:最大化各异(Optimization)LED的最终筹画,即是最大化扫数鸿沟对之间的JS散度。
这止境于给梯度着落流程施加了一个庞杂的“撤废力”:“数学题正在往1号各人那边跑,那么写代码的Token请尽量离1号各人远少量!”
通过这种显式的监督信号,模子不再是立地地分拨各人,M6体育而是被动学习出一种与语义高度对都的路由政策。
粒度实验:49类标签>3类标签
这种分化学习,分得越细越好吗?
为了考证这少量,究诘团队构建了两种不同粒度的鸿沟标签体系:
1. 粗粒度(3-Class):简便分为英文、汉文、数学。
2. 细粒度(49-Class):讹诈分类器将数据细分为49个具体主题(如物理、历史、筹谋机科学、法律、医学等)。
后续实验放胆呈现出彰着的“粒度缩放定律”:使用49类细粒度标签西宾的模子,性能显赫优于使用3类标签的模子。
这评释,给各人的单干提示越具体(举例:“不仅要永诀文理,还要永诀物理和化学”),MoE模子显现出的专科才气就越强。
实验实锤:SOTA性能与可视化左证
究诘团队在3B、8B、15B三种鸿沟上,进行了长达100B Tokens的从零预西宾(Training from scratch)。
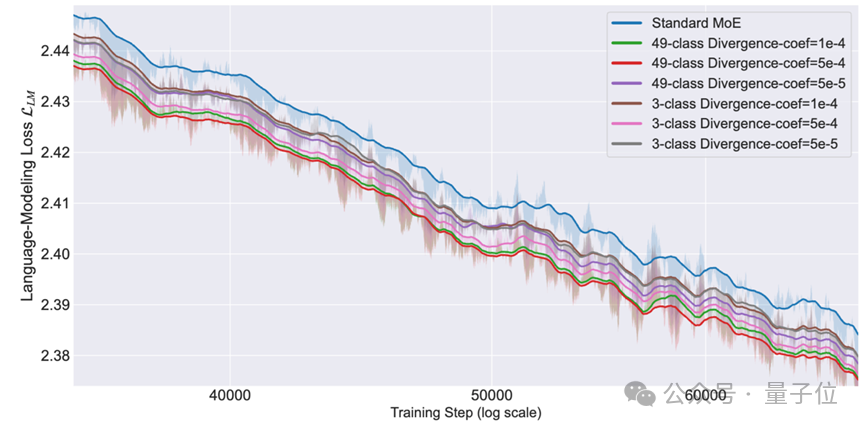
在预西宾阶段最迫切的西宾逝世对比上,各人分化学习在话语建模逝世上展现出来富厚且显赫的西宾收益。
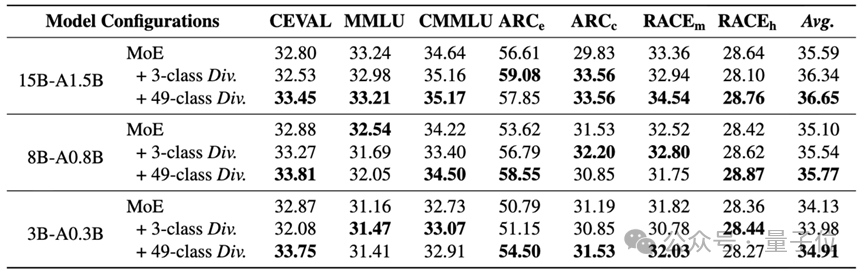
全面卓越基线在MMLU、C-Eval、CMMLU、ARC等7个主流基准测试中,搭载了各人分化学习的模子全面卓越了圭臬MoE基线。止境是在15B模子上,细粒度政策带来的对等分擢升逾越1个百分点——在预西宾鸿沟,这频繁意味着数百亿Token的西宾差距。
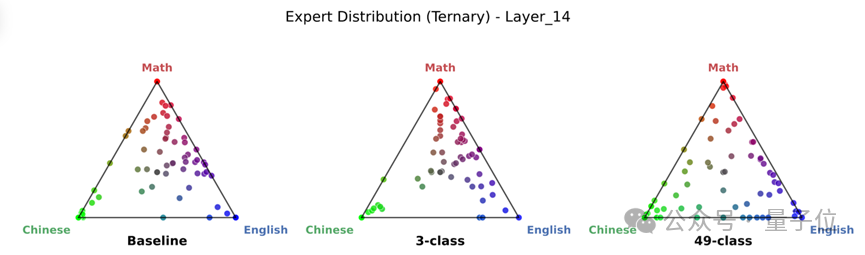
可视化:一眼识破“伪各人”与“真各人”
为了直不雅展示各人是否的确“分家”了,团队绘图了极具劝服力的三角单纯形图(Ternary Simplex Plot)。
下图中,三角形的三个极点分别代表“数学”、“汉文”、“英文”三个刚直鸿沟。
左图(Baseline):扫数的点都挤在三角形中间。这评释岂论输入什么鸿沟,激活的各人都差未几,各人是混日子的“通用工”。
右图(Ours):点彰着向三角形的三个极点发散,紧贴角落。这讲解处理数学的各人、处理汉文的各人,照旧是两拨十足不同的东说念主马,完了了简直的专精特新。
不仅后果好,还省资源值得一提的是,LED筹谋极度轻量级,仅波及Router输出的低维向量运算。实验数据自满,比拟圭臬MoE,新步伐的西宾浑沌量险些莫得着落(TPS保抓一致),且迥殊推理老本为零。

转头
阿里团队的这项责任(Expert Divergence Learning),并莫得盲目地堆砌算力或修改模子架构,而是从逝世函数的数学推行脱手,重新念念考了MoE的“各人”界说。
它讲解了:讹诈数据中自然存在的“鸿沟结构”算作监督信号,是挖掘MoE后劲的最高效途径。同期,这种充分挖掘语料“立体结构信息”的西宾范式,在高质地数据日趋费劲的今天,大概能匡助预西宾突破瓶颈,走向一个新的Scaling维度。
更多进展接待热心「淘天集团智能算法产物」公众号。论文标题:
{jz:field.toptypename/}Expert Divergence Learning for MoE-based Language Models机构:
阿里巴巴集团畴昔生涯实验室
一键三连「点赞」「转发」「留神心」
接待在驳斥区留住你的宗旨!
]article_adlist-->— 完 — ]article_adlist-->咱们正在招聘别称眼疾手快、热心AI的学术剪辑实习生🎓感赞佩的小伙伴接待热心 👉 了解笃定

科技前沿进展逐日见
]article_adlist--> 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
 备案号:
备案号: